

【導(dǎo)讀】實時渲染視頻級別的計算機三維圖形是計算圖形領(lǐng)域的終極目標(biāo),與現(xiàn)在普遍使用的光柵化渲染技術(shù)相比,光線追蹤普遍被視為視覺技術(shù)的未來方向,可帶來近乎真實的真正電影級圖形和光影物理效果,光線追蹤算法是達(dá)到這個目標(biāo)的圣杯,經(jīng)過幾十年的努力,終于要接近這個理想了。
光線追蹤的定義和原理
精美的CG效果圖,與真實,相信大家對這些并不陌生。而大家在游戲中對水面之類的場景并不陌生,不過它所生成的畫面效果,好像永遠(yuǎn)都不那么真實。即使人們盡再大的努力,它的畫面始終還是動畫,和人們心目中的“電影級別的畫質(zhì)”總是差那么一點。這是因為,我們目前的游戲,無一例外都在使用光柵化算法。而在這些電影中,則采用的是光線追蹤算法。在3DSMax、Maya、SoftimageXSI等軟件中,也都無一例外地采用了這一算法。
光線追蹤技術(shù)是由幾何光學(xué)通用技術(shù)衍生而來。它通過追蹤光線與物體表面發(fā)生的交互作用,得到光線經(jīng)過路徑的模型。
簡單地說,3D技術(shù)里的光線追蹤算法,就是先假設(shè)屏幕內(nèi)的世界是真實的,顯示器是個透明的玻璃,只要找到屏幕內(nèi)能透過人眼的光線,加以追蹤就能構(gòu)建出完整的3D畫面。
說到光線追蹤,就不得不提光柵化。
光柵化是指把景物模型的數(shù)學(xué)描述及其色彩信息轉(zhuǎn)換至計算機屏幕上像素的過程。使用光柵化,我們可以將幾何圖形轉(zhuǎn)化成屏幕上的像素。
Direct3D使用掃描線的渲染來產(chǎn)生像素。當(dāng)頂點處理結(jié)束之后,所有的圖元將被轉(zhuǎn)化到屏幕空間,在屏幕空間的單位就是像素。點,線,三角形通過一組光柵規(guī)則被轉(zhuǎn)化成像素。光柵規(guī)則定義了一套統(tǒng)一的法則來產(chǎn)生像素。光柵得到的像素一般會攜帶深度值,一個RGB Adiffuse顏色,一個RGB specular顏色,一個霧化系數(shù)和一組或者多組紋理坐標(biāo)。這些值都會被傳給流水線的下一個階段像素的處理,然后注入到渲染目標(biāo)。由于實時3D渲染程序要求對用戶的即時操作做出迅速反應(yīng),因此通常要求每秒至少20幀以上的渲染速率,這也使得高效率的“光柵化”渲染技術(shù)成為當(dāng)今最受青睞的3D即時成像技術(shù)。但是光柵化的缺點也很明顯,那就是無法計算真實的光線,導(dǎo)致很多地方失真。
光線追蹤算法分為兩種:正向追蹤算法和反向追蹤算法。
其中,正向追蹤算法是大自然的光線追蹤方式,即由光源發(fā)出的光經(jīng)環(huán)境景物間的多次反射、透射后投射到景物表面,最終進(jìn)入人眼。
反向追蹤算法正好相反,它是從觀察者的角度出發(fā),只追蹤那些觀察者所能看見的表面投射光。就目前而言,所有3D制作軟件的光線追蹤算法都是采用反向追蹤法,原因是這種算法能夠最大程度地節(jié)省計算機的系統(tǒng)資源,而且不會導(dǎo)致渲染質(zhì)量的下降。
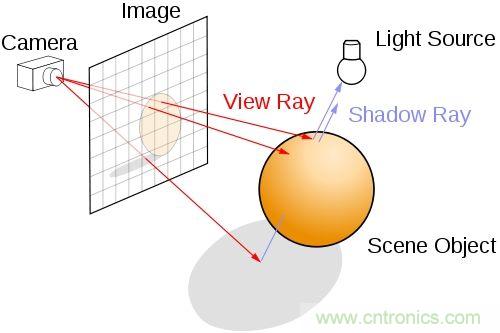
在現(xiàn)實世界中射到物體表面上通常有三種情況:折射,反射,吸收。光線在經(jīng)過反射到不同的地方,被選擇性吸收,從而光譜發(fā)生改變,再多次反射與折射,最終進(jìn)入我們自己的眼睛。而光線追蹤技術(shù)要做的就是模擬這一過程。
在渲染中,光線追蹤會賦予每一個像素幾條甚至幾十條光線,然后光在場景中傳播,與場景中各個物體產(chǎn)生交匯,而場景中的物體在事先就已經(jīng)被開發(fā)者設(shè)置好了屬性,從而導(dǎo)致光束發(fā)生各種改變,最終聚集在屏幕上。從而被我們感知。
而反向追蹤方式則是計算最終射入我們眼睛的光線的反向光路,即眼睛—物體—光源的過程。因為這么做的話,可以省掉很多并不需要計算的光路,在光線追蹤中,并不是每一束光都有用。有些光最終并沒有射入我們自己的眼睛,但是如果依舊計算的話就會造成不必要的計算資源浪費。在光線追蹤中,光同樣也被分類,假設(shè)一條主光線是不可見的,那么系統(tǒng)則會拋棄掉整條光路,如果可見的話,那么輔助光線(反射,折射,陰影)的計算就開始了。在完成主光線的判別之后,輔助光線的其他屬性(透明度,色彩)操作也已經(jīng)基本完成了。
光線追蹤在圖形渲染中的應(yīng)用
將光線追蹤算法應(yīng)用于圖形渲染最初是由Arthur Appel于1968年提出,那時還叫ray casting。
1979年Turner Whitted帶來了新的研究突破:遞歸光線追蹤算法《Recursive RayTracing Algorithm》。
1984年,Carpenter等人發(fā)表了一篇分布式光線追蹤的論文《Distributed RayTracing》,影響甚廣。發(fā)展到今天,大多數(shù)的照片級渲染系統(tǒng)都是基于光線追蹤算法的?;镜墓饩€追蹤算法并不難,相信大部分計算機圖形學(xué)的同學(xué)都寫過的,難的是如何優(yōu)化提高效率。
說到皮克斯直到《汽車總動員》才開始大規(guī)模使用光線追蹤。皮克斯的《汽車總動員》于2006年6月在美國上映,如今已經(jīng)8年多過去了。皮克斯一直使用的是自家開發(fā)的渲染器RenderMan,基于REYES(Renders Everything You Ever Saw)。
REYES是另一種渲染算法,它對于處理復(fù)雜場景非常高效。
1984年的時候皮克斯有考慮過光線追蹤,但最終還是堅持使用REYES。那篇關(guān)于《汽車總動員》的論文《RayTracing for the Movie“Cars”》里提到五年前他們就啟動了添加光線追蹤功能到RenderMan這個項目,同期《汽車總動員》正在制作中。REYES在處理反射強烈的汽車表面材質(zhì)方面有些捉襟見肘,只能用環(huán)境貼圖,但仍然達(dá)不到光滑閃耀的質(zhì)感。而這正是光線追蹤擅長的。
下面介紹幾個使用光線追蹤的主流渲染器:
Mentalray,NVIDIA出品,已經(jīng)集成到3D建模軟件Autodesk的Maya和3ds Max中。
Arnold近些年日漸風(fēng)行,Sony Pictures Imageworks,Digital Domain,ILM,Luma Pictures等著名特效公司均有使用該渲染器。
VRay,比Arnold大眾一點,近幾年也在瘋長,它目前有CPU版本和GPU版本(V-Ray和V-Ray RTGPU)。
光線追蹤目前多用于影視特效中做靜幀渲染,但對大眾最有影響的3D圖形游戲領(lǐng)域顯然還沒有光線追蹤的蹤影,這是為什么呢?
光線追蹤遲遲不能應(yīng)用在游戲行業(yè)中的原因很簡單——它那恐怖的計算量。即便是用了反向追蹤算法之后也是如此。
根據(jù)Intel的說法,要用光線追蹤渲染出達(dá)到現(xiàn)代游戲的畫面質(zhì)量,同時跑出可流暢運行的幀數(shù),每秒需要計算大概10億束光線。這個數(shù)字包括每幀每像素需要大概30束不同的光線,分別用來計算著色、光照跟其它各種特效,按照這個公式,在1024×768這樣的入門級分辨率下,一共有786432個像素,乘以每像素30束光線以及每秒60幀,我們就需要每秒能運算141.5億束光線的硬件。
而即便到了今天,頂級的Corei7每秒能處理的光線還不足千萬條。而且這只是運算量上的差距,由于光線追蹤的輔助光線每一條都沒有任何相關(guān)性,這意味著包括各種緩存技術(shù)在內(nèi)的“投機取巧”方式都沒有用武之地,計算光線追蹤輔助光線的所有的計算都將直接讀取內(nèi)存,這對于內(nèi)存延遲和帶寬來說都是驚人的考驗。而且對于顯存容量也是一個不小的挑戰(zhàn),十幾甚至幾十GB的顯存會變的非常有必要。
雖然在游戲領(lǐng)域引入光線追蹤是有極大挑戰(zhàn)的事情,但這項技術(shù)一直有研究機構(gòu)和圖形處理器廠商在投入研究。光線追蹤若想要應(yīng)用到游戲中就需要做到實時渲染,就是大家所說的實時光線追蹤(Real-time raytracing)。
光線追蹤算法前面說過了,那什么樣才是實時的?
6FPS左右就可以產(chǎn)生交互感,15FPS可稱得上實時,30fps不太卡,60FPS感覺平滑流暢,72FPS再往上肉眼就已經(jīng)分辨不出差別。
所謂實時就是需要達(dá)到每秒渲染30幀以上,否則就達(dá)不到畫面的流暢度要求,就沒有實用價值。實時的光線追蹤的難點就在于場景復(fù)雜度和需要的真實感渲染效果決定了遍歷和相交檢測的巨大計算量(場景分割數(shù)據(jù)結(jié)構(gòu)的重構(gòu)和光線與場景的相交測試是兩項主要計算)。
這是渲染領(lǐng)域以及任何模擬計算領(lǐng)域里終極的矛盾:效率和質(zhì)量的矛盾。
實時光線追蹤技術(shù)發(fā)展歷史
隨著德國薩爾蘭大學(xué)計算機圖形小組所開發(fā)的OpenRT庫的完成,光線追蹤技術(shù)應(yīng)用在電腦游戲的實時渲染中在理論上逐漸成為可能。
OpenRT函數(shù)庫是源自薩爾蘭大學(xué)的一個計算機圖形小組的實時光線追蹤項目,OpenRT實時光線追蹤項目的目標(biāo)是為3D游戲加入實時的光線追蹤效果,該項目會包含以下幾個部分:一個高效的光線追蹤處理核心、以及語法與目前OpenGL類似的OpenRT 應(yīng)用程序接口,客戶程序員通過這部分接觸之前高效的光線追蹤處理核心的功能,并在游戲場景設(shè)計中調(diào)用這些應(yīng)用程序接口。
薩爾蘭大學(xué)除了開發(fā)出了OpenRT函數(shù)庫外,還設(shè)計了一個實時光線追蹤的硬件架構(gòu)——SaarCOR。SaarCOR研究小組在2005年的SIGGRAPH上展示了第一個實時光線追蹤加速硬件——RPU(Ray Processing Unit)。
RPU跟GPU一樣都是完全可編程架構(gòu),能夠提供對材質(zhì)、幾何以及光照等的實時編程支持。
RPU除了具有傳統(tǒng)GPU的高效性外,最引人矚目的就是支持光線追蹤計術(shù)。其使用的指令集跟GPU一樣,因此也能夠?qū)χ绦蜃鲎罴鸦幚怼?/div>


 [page]
[page]



此外,由于集成了專用的硬件單元,RPU可以支持高速光線跟蹤算法跟遞歸函數(shù)調(diào)用,對于遞歸光線追蹤算法同樣行之有效。為了提高執(zhí)行效率,RPU通常將4束光線打包處理,同時多線程計術(shù)的支持也保證了硬件資源的高效利用。
SaarCOR在SIGGRAPH 2005展示的RPU原型機用FPGA來構(gòu)建,頻率運行在66MHz,內(nèi)存帶寬也只有350MB/s,但是得益于特別設(shè)計的專用架構(gòu),其性能可以跟P4 2.6G的CPU跑OpenRT軟件光線追蹤的性能相媲美。
這樣的性能充分體現(xiàn)出RPU架構(gòu)在處理光線追蹤方面的高效性,要知道NV當(dāng)時的高端GPU可是具有RPU原型機23倍的浮點運算能力以及100多倍的帶寬。
更令人興奮的是,由于光線追蹤特別適用于并行處理的天生特性,RPU可以像CPU一樣采用多核架構(gòu),原型機可以搭配不同數(shù)量的FPGA芯片,比如兩片F(xiàn)PGA就可以提供雙倍于單FPGA的運算能力,而SaarCOR試驗室已經(jīng)測試過四FPGA的原型機。
就在SaarCOR展示了RPU之后不久,這個研究計劃的人員接觸到了IBM德國的技術(shù)人員,獲得了一臺擁有一枚CELL處理器的工程樣機。在IBM技術(shù)人員的協(xié)助下,SaarCOR在短短兩周的時間里就在這臺機器上實現(xiàn)了全屏的實時光線追蹤渲染效果。SaarCOR的研究人員目前已經(jīng)在Cinema 4D上以插件方式實現(xiàn)了實時光線追蹤。他們還透露了另外一個鮮為人知的消息,那就是SaarCOR其實獲得了NVIDIA 2.5萬美元的贊助,之前的FPGA原型其實就是在NVIDIA資助下進(jìn)行的。SaarCOR至今未能量產(chǎn),隨后SaarCOR項目并入了OpenRT光線追蹤開發(fā)項目中。
早在十多年前的2004年,德國青年 Daniel Pohl將一款電腦游戲應(yīng)用光線追蹤技術(shù)作為其學(xué)術(shù)研究項目。因為ID software的開源,所以《Quake3》成為了他的選擇,并開始移植。
他用OpenRT對其渲染核心進(jìn)行改造,令人驚訝的是在《Quake3》傳統(tǒng)的光柵化渲染上實現(xiàn)光線追蹤居然顯得出奇的簡單。例如在每個像素的動態(tài)、實時陰影僅需要10行左右的代碼指令來描述光線追蹤的模型。光線追蹤技術(shù)的加入令整個游戲的光影效果煥然一新。畫面甚至超過了很多后來發(fā)布的新游戲。之后的幾年里,Daniel Pohl更將注意力放到了《Quake 4》、《Quake War》等游戲上,試圖在這些游戲中實現(xiàn)實時光線追蹤算法。有趣的是,Daniel Pohl的實時光線追蹤技術(shù)完全不依賴于GPU,僅僅是借助多核CPU的運算能力。也正因為如此,Daniel Pohl隨后被Intel高薪聘用,正式加盟其“視覺運算部”,由此可以看出Intel決心令實時光線追蹤成為現(xiàn)實。
Intel想進(jìn)軍獨立顯卡市場已經(jīng)不是一天兩天了。上世紀(jì)末intel就曾經(jīng)出過一款獨顯,名叫i740。但是也僅僅就這一款而已。一心想要重返顯卡市場的intel想以光線追蹤來抗衡AMD與NVIDIA,所以研究光線追蹤的天才程序員DanielPohl被intel收歸門下,進(jìn)行顯卡的開發(fā)。
在2007年的IDF上,Intel正式揭開獨立顯卡——代號“Larrabee”的神秘面紗,Larrabee隸屬于其萬億次運算項目(Tera-scale),也將是Intel的第一款實用級萬億次運算處理器,其處理能力“大大超過”一萬億次浮點每秒;根據(jù)Intel首席架構(gòu)師EdDavis的演示文稿,Larrabee基于可編程架構(gòu),主要面向高端通用目的計算平臺,至少有16個核心,主頻1.7-2.5GHz,功耗則在150W以上,支持JPEG紋理、物理加速、反鋸齒、增強AI、光線追蹤等特性。
由于天生的CPU傳統(tǒng)架構(gòu)血統(tǒng),Larrabee特別適合用來計算光線追蹤。
在IDF2007的技術(shù)演示中,Intel也特意大張旗鼓地宣傳Larrabee在實時光線追蹤領(lǐng)域所取得的最新成就。但是Larrabee卻并沒有想象中的那么順利,在2009年的IDF大會上,我們看到了新的Corei7系列,Atom雙核,而Larrabee卻被冷落在一旁,這不得不令人惋惜。、
作為一款中途夭折的產(chǎn)品,Larrabee在很多人的心目中應(yīng)該一直都保留著幾分神秘色彩,最后該項目的不了了之,還是給實時光線追蹤的發(fā)展帶來了些許遺憾。大家也都知道最后Larrabee的技術(shù)是用到了“眾核架構(gòu)”(MIC)的XeonPhi協(xié)處理器當(dāng)中,成為Intel在高性能計算領(lǐng)域和GPU廠商的加速卡競爭的利器
就在Larrabee項目中途夭折以后,實時光線追蹤技術(shù)似乎裹足不前了。但在2009年3月,一家名不見經(jīng)傳的初創(chuàng)公司Caustic Graphics突然浮出水面,帶來了一種具有突破性意義的實時光線追蹤軟硬件解決方案,號稱可提速200倍,業(yè)內(nèi)震驚。
其管理團(tuán)隊聚集了來自蘋果、Autodesk、ATI、Intel、NVIDIA等業(yè)界巨頭的技術(shù)與圖形專家,三位創(chuàng)始人James McCombe、Luke Peterson、Ryan Salsbury曾經(jīng)在蘋果共事,其中McCombe被譽為是OpenGL世界的“第三號人物”,同時也是iPhone、iPod等嵌入式、低功耗平臺光柵化渲染算法的首席架構(gòu)師。
CausticGraphics聲稱一舉解決了光線追蹤算法效率低下的難題。
根據(jù)該公司的說法,他們的算法之所以獨特是因為它解決了傳統(tǒng)光線追蹤算法偏向隨機性的問題。新算法大幅提高了光線追蹤計算的局部性,但這部分的算法需要一顆協(xié)處理器來完成。Caustic Graphics的工程師們相當(dāng)明智,他們對于該硬件的定位僅僅是一顆專注于光線追蹤運算的協(xié)處理器,而絕不會干越俎代庖的蠢事,著色之類的傳統(tǒng)光柵化處理依舊由GPU來完成。
除此以外,在2009年8月的SIGGRAPH會議上,圖形處理器巨頭Nvidia發(fā)布了OptiX,這是一個基于Nvidia GPU的實時光線追蹤加速引擎。
在功能上,Optix引擎與前面介紹的OpenRT類似,都是一組光線追蹤的函數(shù)庫,Nvidia在介紹中說optix引擎基于CUDA架構(gòu),開發(fā)者可以使用C語言編程,創(chuàng)造出基于GPU運算的光線追蹤應(yīng)用。我們有足夠的理由相信,Optix所用的光線追蹤模型,極有可能與SAARCOR的OpenRT 引擎相同,或者說OPTIX只是OpenRT的NVIDIA商用化版本。但由于光線追蹤的算法和傳統(tǒng)光柵化處理算法區(qū)別較大,現(xiàn)有SIMD架構(gòu)的GPU內(nèi)核在計算光線追蹤算法時的效率不高,完全用傳統(tǒng)GPU來加速光線追蹤的做法至今也沒有成功進(jìn)入游戲領(lǐng)域。
另外,NVIDIA目前已經(jīng)有virtual GPU技術(shù),類似于云計算,不需要本地的GPU,但該技術(shù)進(jìn)入大眾消費市場應(yīng)該還有很長的路要走。
Imagination夢想照進(jìn)現(xiàn)實
可能很多人不知道的是,在移動GPU領(lǐng)域呼風(fēng)喚雨的另一個隱形巨頭Imagination,其實也在努力摘取這個3D圖像處理皇冠上的明珠,只不過它的做法比較出人意料,在2010年底突然收購了前文介紹過的創(chuàng)業(yè)公司Caustic Graphics,并在2013年初推出了光線追蹤專用加速卡,不過該產(chǎn)品只針對專業(yè)市場,并未掀起業(yè)界的大波瀾。但在去年3月的GDC2014游戲開發(fā)者大會上,Imagination正式發(fā)布了全新的“PowerVR Wizard”GPU家族,號稱可在適合移動、嵌入式應(yīng)用的功耗水平下,提供高性能的光線追蹤、圖形和計算能力,這次真正震動了業(yè)界(筆者看到這個新聞的時候的確是不敢相信)。
新家族的第一名成員是PowerVR GR6500,基于最新一代的四陣列移動GPU PowerVR Rogue設(shè)計而來,整合了PowerVR Series6 XT系列的所有特性,并加入了強大的光線追蹤硬件加速電路。
硬件的優(yōu)化可以分為采用GPU和SIMD的優(yōu)化以及專門的光線追蹤硬件。前者就是對軟件算法進(jìn)行針對GPU或SIMD的優(yōu)化,同時一些并行環(huán)境下的數(shù)學(xué)庫函數(shù)和其他基本算法,如排序等也間接起到了加速的作用。后者就是指將光線追蹤中獨有的相交檢測,場景分割等部分采用專門的硬件來優(yōu)化,G6500就是使用后面一種優(yōu)化,這些專用加速電路包括:
光線數(shù)據(jù)主控(Ray Data Master):為主調(diào)度器提供光線交互數(shù)據(jù),準(zhǔn)備給著色器執(zhí)行,并評估光線的最終數(shù)據(jù)屬性。
光線追蹤單元(Ray Tracing Unit):使用固定函數(shù)(不可編程)執(zhí)行光線追蹤遍歷隊列,并匯總光線一致性,以降低功耗和帶寬需求。
場景層次生成器(Scene Hierarchy Generator):加速動態(tài)物體的更新。
幀收集器緩存(Frame Accumulator Cache):提供對幀緩沖的寫入合并松散式訪問。
從芯片的架構(gòu)圖圖可以看出,所有這些設(shè)計都可以和GPU架構(gòu)的其他模塊高效整合、完美通信,生成實時、交互的光線追蹤畫面,而且不僅適用于移動、嵌入式平臺,還能擴(kuò)展到主機和主流游戲PC。更重要的是,這些模塊不會影響傳統(tǒng)圖形流水線的著色性能,因為它們并非依賴著色器的浮點性能來執(zhí)行光線追蹤,效率最多可以達(dá)到純GPU計算或者軟件算法的100倍。
那么,PowerVR GR6500的光線追蹤性能究竟如何呢?
Imagination宣稱,600MHz頻率下每秒可追蹤最多3億束光線,進(jìn)行240億次節(jié)點測試,生成1億個動態(tài)三角形。由于還沒有實體的芯片問世,現(xiàn)在只有理論數(shù)值。當(dāng)年Caustic Graphics曾經(jīng)透露,完全光線追蹤化的游戲引擎還得等很多年,并估計至少四五年后他們的硬件才能在1920×1080分辨率下達(dá)到60FPS的有效幀率。
當(dāng)時是2009年,這兩年正好是這個時候,我們相信由于Imagination的支持,性能應(yīng)該能夠達(dá)到當(dāng)年Caustic Graphics的預(yù)測水平,從而達(dá)到主流游戲的運行要求。
Imagination還開發(fā)了跨平臺的OpenRL API,并放出了SDK,希望開發(fā)人員能夠參與其中。
據(jù)說OpenRL還在申請成為國際標(biāo)準(zhǔn),希望成為OpenGL這樣的跨平臺標(biāo)準(zhǔn)API。當(dāng)然這個API也是來自于原來Caustic Graphics的軟件開發(fā)層Caustic GL,由于其創(chuàng)始人具有非常強的OpenGL專業(yè)背景,Caustic并沒有自己去開發(fā)一套專用的API,而是基于OpenGL ES2.0編寫擴(kuò)展子集,并將其命名為Caustic GL。
采用OpenRL的最大優(yōu)勢,就是允許開發(fā)人員像往常編寫著色程序那樣來編寫新的光線追蹤著色程序,而一些原本非常復(fù)雜的光影著色程序(用于創(chuàng)建復(fù)雜的光照跟投影效果)則可以由簡單的光線追蹤著色程序來代替,這樣既可以減輕程序員的負(fù)擔(dān)還可以提升硬件效率。
開發(fā)人員還可以將OpenRL與其他圖形API相結(jié)合,比如OpenGL3/3.1,未來甚至能夠與DX混合調(diào)用。另一個有趣的特性是OpenRL并非光線追蹤硬件加速電路專用,它同樣支持GPU,所以在沒有硬件加速電路的系統(tǒng)里,光線追蹤計算也可以交由GPU來負(fù)責(zé),當(dāng)然效率將大打折扣。
從以上的介紹我們可以看出Imagination已經(jīng)徹底把CausticGraphics的軟硬件技術(shù)集成到自己的GPU里面,并由此提供了極具競爭力的實時光線追蹤性能,而仍舊保持了低功耗和低成本的特色,將會給整個圖形市場帶來顛覆性的影響。
移動GPU第一次走在了桌面GPU的前面,相信這對于Imagination擴(kuò)大整體GPU市場占有率會帶來極大的推動力。Imagination也可以借此進(jìn)入被NV和AMD所把持的桌面和專業(yè)圖形市場。
當(dāng)年ARM處理器由于性能不佳,只能退守深耕移動和嵌入式市場,不料反倒獲得巨大成功成為當(dāng)代最有影響力的處理器指令集架構(gòu),甚至開始進(jìn)軍桌面和服務(wù)器市場,Imagination似乎也開始走上了這條逆襲之路。



